PROGRAM
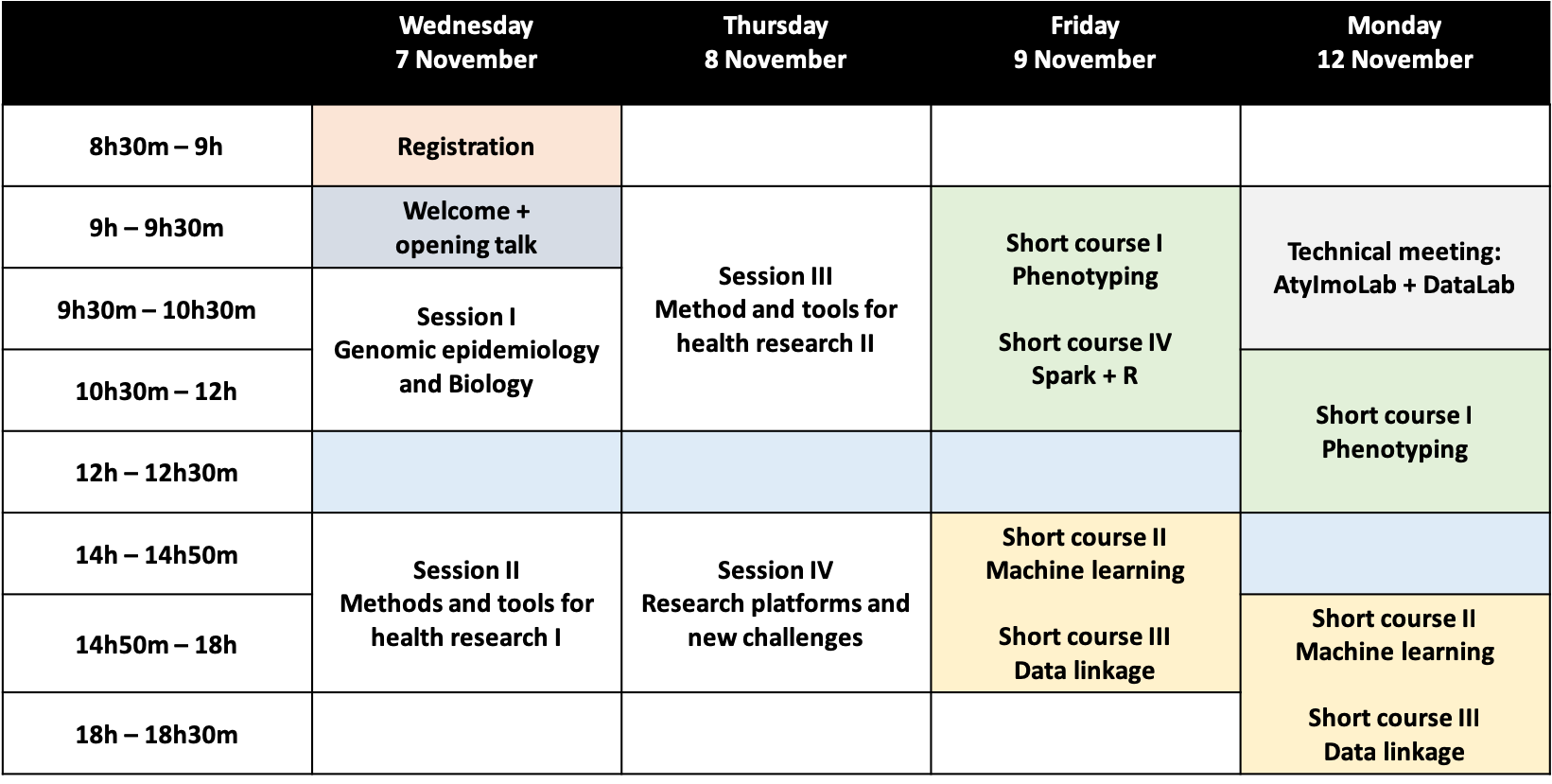
WEDNESDAY, 7 NOVEMBER 2018
- 9h - 9h10m | Introduction and Agenda
- Marcos Barreto (UFBA & CIDACS) (Slides)
- 9h10m - 9h30m | Opening talk
- Overview of CIDACS' data and research platforms
- Mauricio Barreto (CIDACS)
- SESSION I: GENOMIC EPIDEMIOLOGY AND BIOLOGY
- 9h30m - 10h | Invited talk: The EPIGEN-Brasil Initiative
Eduardo Tarazona (Federal University of Minas Gerais) - 10h - 10h30m | Invited talk: Data harmonisation in diverse datasets
Vaclav Papez (University College London)- (Slides)
Abstract: This talk will discuss various approaches for harmonizing EHR for research. Firstly, we will cover approaches for data standardization such as the OMOP Common Data Model. We will additionally cover two technologies used for creating computable representations for EHR phenotypes from the Semantic Web (SWT), the Web Ontology Language and the Resource Description Framework (RDF). We will discuss and critically appraise the different options for managing the process of semi-automatic phenotype ontology generation and consequent reasoning in order to retrieve patient cohorts which can then be used for research. - 10h50m - 12h | Panel: Mathematical modelling
- 10h50m - 11h10m | Mathematical modelling of epidemics: the challenge of using big data to study
the dissemination of Zika, Dengue and Chikungunya viruses in Camaçari
Juliane Fonseca (CIDACS), Roberto Andrade (UFBA) - (Slides)
Abstract: The emergence and rapid spread of Zika virus in Brazil surprised arbovirologists and public health officials. The initial difficulty was in identifying this virus among clinical episodes initially notified as infections by Dengue and Chikungunya viruses, which were known to be present in the country. Since the outbreak of the disease, several works have addressed the transmission and spread of Zika virus in the population. However, an important factor in these analyzes has been left behind: the cases of Zika infections that were neglected, i.e., generally classified as unspecific exanthematic occurrences. Here we discuss the challenge in dealing with these cases. Particularly attention is given to data of exanthematic notifications during the year 2015 in Camaçari, Brazil, the first city in the state of Bahia where Zika cases were notified. - 11h10m - 11h30m | The fantastic worlds of Genomics and Epidemiology meet themselves: The EGGS initiative
Larissa Catharina Costa (CIDACS), Artur Trancoso (CIDACS)
Abstract: Zika virus (ZIKV) is a mosquito-transmitted Flavivirus that has emerged as a global health threat because of its potential to generate explosive outbreaks and ability to cause congenital disease during pregnancy. Despite several works have been published, until now much remains unknown about ZIKV disease epidemiology and ZIKV evolution, in part owing to a lack of genomic data. In this talk, we will present The Epidemiological Genomical Geographic Surveillance (EGGS) initiative which combines epidemiology and genomic data of cases occurred in Brazil since the beginning of the outbreak. - 11h30m - 12h | Discussion
- SESSION II: METHODS AND TOOLS FOR HEALTH RESEARCH I
- 14h - 14h30m | Invited talk: Data visualization: methods and tools
Danilo Coimbra (UFBA) - 14h30m - 18h | Panel: Linkage and accuracy assessment
- 14h30m - 14h50m | CIDACS' data linkage tools
George Barbosa (CIDACS), Robespierre Pita (CIDACS), Marcos Barreto (UFBA)
Abstract: This talk will present two linkage tools (AtyImo and CIDACS-RL) which are used to support data linkage tasks inside CIDACS. Routines for data preprocessing, indexing, blocking, and anonymization will be discussed. Deterministic and probabilistic approaches will be also presented, as well some technical issues related to pairwise matching (linkage attributes, cut-off points) and validation (test samples and gold standards). - 14h50m - 16h10m | Challenges in using linked electronic health records for research
Dandara Ramos (CIDACS), Daiane Machado (CIDACS), Julia Pescarini (CIDACS) - 16h10m - 16h30m | Challenges in the accuracy assessment of linkage
Rosemeire Fiaccone (UFBA) - 16h30m - 16h50m | Effects of linkage errors on epidemiological analysis
Elizabeth Williamson (London School of Hygiene and Tropical Medicine) - (Slides)
Abstract: Large linked data are increasingly used to address a wide range of health questions. While much methodological work has focused on how to conduct linkage, and how to assess the success and accuracy of the linkage, less work has been undertaken to explore the effects of linkage error on the results of subsequent epidemiological analysis of the linked data. The impact of errors, both missed matches and false matches, will depend both on the amount and type of linkage errors, but also on the analysis being undertaken. This talk will explore the effect of linkage errors on the results of common epidemiological analyses, in a number of different scenarios. - 17h - 18h | Discussion
THURSDAY, 8 NOVEMBER 2018
- SESSION III: METHODS AND TOOLS FOR HEALTH RESEARCH II
- 9h - 9h30m | Invited talk: Mathematical modelling in the real world: from the
2015-2016 Zika outbreak in Cape Verde to serological approaches for tackling the epidemiology of malaria
Nuno Sepúlveda (London School of Hygiene and Tropical Medicine)
Abstract: For many researchers, mathematical modelling of infectious diseases is usually shrouded in a mysterious aura of complex formulas whose symbols can only be understood by Greek nationals and a few devoted aficionados. It is also perceived as a research field living in the realm of ideal worlds far away from the mundane activities of disease control, surveillance and elimination. To contradict this general perception, I will explore two recent examples from the real world. The first example is the analysis of the 2015-2016 Zika outbreak in Cape Verde, a small archipelago country off the coast of West Africa where there were more than 7,500 suspected cases. The second example refers to the estimation of malaria transmission intensity using serological (or antibody) data. In the current era of big data, these two examples show the pressing necessity of linking serological data with official health records (or vice-versa). This linkage is expected to enable the reconstruction the infection history of a given population. This reconstruction, if successfully achieved, brings the promise of improving decisions about the future priorities in infectious diseases.
- 9h30m - 10h | Invited talk: Data-driven tools for disease prognosis
Spiros Denaxas (University College London)
Abstract: Disease prediction tools enable clinicians to identify patients at higher risk of developing a particular health outcome such as a diagnoses or complications association with a disease, being hospitalized (or re-hospitalized) or dying from a specific condition. The majority of tools however do not fully exploit the richness and resolution of available data as they tend to use a small set of manually curated clinical features and traditional statistical modelling approaches. This talk will illustrate and critically appraise the use of machine learning approaches including as supervised learning algorithms and neural network representations of clinical concepts for developing and evaluating risk prediction tools using all available data on millions of patients. - 10h - 12h | Panel: Machine and deep learning
- 10h - 10h20m | Machine learning for subtype discovery in COPD using primary care Electronic Health Records
Maria Pikoula (University College London) - (Slides)
Abstract: Chronic obstructive pulmonary disease (COPD) is a highly heterogeneous disease composed of different phenotypes with different aetiological and prognostic profiles and current classification systems do not capture this heterogeneity. In this talk, we will discuss the discovery and validation of disease subtypes using data-driven methods such as clustering in the context of COPD using EHR data across healthcare settings from the CALIBER platform. The talk will cover the technical pipeline and discuss the challenges and opportunities presented with implementing similar studies in EHR data along with best practices. - 10h40m - 11h | Application of multiobjective grammar-based genetic programming to identify relationships of risk factors in asthma
Rafael Veiga (CIDACS)
Abstract: Genetic algorithms are optimization techniques inspired on evolution by natural selection. These techniques have been very successful in solving complex problems in different fields. Genetic programming is a specific type of genetic algorithm that is capable of evolving solutions to a wide range of problems. This technique allows for several extensions, such as: grammar-based, which can be defined a formal grammar for constructing solutions; and multiobjective, which can optimize in relation to several goals simutaneously that are not comparable to each other This talk will illustrate the application of multiobjective grammar-based genetic programming to generate models that explain the occurrence of asthma and allergies based on epidemiological data. - 11h - 11h20m | Understading and predicting malaria epidemics
Juracy Bertoldo (UFBA), Alberto Sironi (UFBA), Marcos Barreto (UFBA) - (Slides)
Abstract: This talk will present our ongoing efforts towards the design and validation of a visual mining tool targeting descriptive and predictive analysis of malaria data. Data aggregation from several sources within the Brazilian malaria ecosystem (notification, mortality, climate, vector control) will be discussed, as well routines for descriptive analysis and epidemics prediction. - 11h30m - 12h | Discussion
- SESSION IV: RESEARCH PLATFORMS & OPEN/NEW CHALLENGES
- 14h - 14h30m | Invited talk: How big is your data?
Samuel Victor Macedo (IFPE) - 14h30m - 16h | Panel: Research platforms
- 14h30m - 14h50m | CIDACS's data platform for research in health
Liliana Cabral (CIDACS)
Abstract: We describe CIDACS's data platform for research in health, which comprises the computational infrastructure for managing and integrating large volumes of administrative data from social and health systems from the Brazilian government. The platform enables data production, data curation and data access, while guaranteeing data security, privacy and ethical use of data. - 14h50m - 15h10m | The CALIBER research platform
Arturo Gonzalez-Izquierdo (University College London) - (Slides)
Abstract: EHR records are generated and captured during routine clinical interactions and require a significant amount of pre-processing in order to be transformed to research-ready datasets for statistical analysis The objective of this talk is to showcase the CALIBER research resource linking EHR from primary care (CPRD), hospital care (HES) and mortality (ONS) in 15 million patients in England. CALIBER provides a set of tools and methods for transforming raw EHR into research ready datasets. The CALIBER Data Portal is an open access resources which curates and disseminates EHR phenotypes for researchers in a reproducible manner. CALIBER has been used by more than 50 research groups nationally and internationally. - 15h10m - 15h30m | Discussion
- 15h30m - 17h30m | Panel: Open and new research challenges
- Open questions for debate
Abstract: Nowadays, the hype around Big Data is so intense that it sometimes seems that everything learned in college about sampling and hypothesis testing is not enough, and if the problem is not related to Big Data, it is uninteresting or obsolete. This talk aims to shed some light on the area, expose some basic concepts, and show real-world applications. Maybe your data is not as big as you think.
FRIDAY, 9 NOVEMBER 2018
- 9h - 12h | Short course 1: Phenotyping methods and common data model
- Venue: Instituto de Matemática e Estatística - Lab 140
- Leads: Arturo Izquierdo (University College London), Vaclav Papez (University College London)
Abstract: This course will provide the basic elements for the derivation and validation of clinical, research-ready phenotypes in observational data sourced from linked EHR using the CALIBER research platform as an exemplar. We will illustrate how to implement this process when multiple data sources and controlled clinical terminologies must be combined under a common data model. We will finally provide research exemplars of EHR phenotypes being used for high-resolution clinical epidemiology studies. - 9h - 12h | Short course 4 (in company): Integrando Spark com R para análise de big data
- Venue: Instituto de Matemática e Estatística - Lab 143
- Lead: Samuel Victor de Macedo (Instituto Federal de Pernambuco)
Resumo: É desafiador trabalhar com grandes bancos de dados em R. Dependendo da análise realizada, o tempo de processamento é inviável e, em muitos casos, apenas ler o arquivo já se torna um problema. O sparklyr é um pacote que integra o R com o Spark, uma das ferramentas de Big Data mais utilizadas hoje em dia. Com este pacote, é possível reduzir o tempo de processamento, pois os dados são tratados de maneira distribuída localmente em seu PC ou em um cluster EMR da Amazon, via RStudio Server. Dessa forma, aprender a trabalhar com Big Data torna-se mais acessível, mesmo quando não se tem grande infraestrutura à disposição para lidar com quantidades massivas de dados. - 14h - 18h | Short course 2: Supervised/unsupervised learning methods in electronic health records research
- Venue: Instituto de Matemática e Estatística - Lab 143
- Leads: Maria Pikoula (University College London), Spiros Denaxas (University College London)
Abstract: This course will cover supervised and unsupervised statistical learning approaches applied to EHR. In the context of risk prediction and classification, we will discuss how supervised learning methods can be used to create and validate prognostic risk scores for predicting disease risk. Additionally, the course will cover methods commonly used in the discovery of clinically relevant disease subtypes, including the process of dimensionality reduction, clustering algorithms and clustering evaluation and validation. Finally, we will discuss the challenges, opportunities and best-practices of conducting these types of research studies in observational data from electronic health records. - 14h - 18h | Short course 3: Data linkage (vinculação de dados)
- Venue: Instituto de Matemática e Estatística - Lab 140
- Leads: Juracy Bertoldo (UFBA), Alberto Sironi (UFBA), Robespierre Pita (UFBA), Marcos Barreto (UFBA)
Abstract: This course will be organized in two parts. The first part concentrates on important concepts related to a data linkage pipeline, such as data quality (missing data), data preprocessing and linkage methods. We will discuss deterministic and probabilistic linkage methods, as well some uncertainty concepts related to probabilistic data linkage. Accuracy assessment will be discussed as an important step to certify linkage results. The second part will be practical, in which attendees will have access to a data linkage tool and will execute all the steps presented in a data linkage pipeline.
MONDAY, 12 NOVEMBER 2018
- 10h40m - 12h30m | Short course 1: Phenotyping methods and common data model
- Venue: Instituto de Matemática e Estatística - Lab 143
- Leads: Arturo Izquierdo (University College London), Vaclav Papez (University College London)
Abstract: This course will provide the basic elements for the derivation and validation of clinical, research-ready phenotypes in observational data sourced from linked EHR using the CALIBER research platform as an exemplar. We will illustrate how to implement this process when multiple data sources and controlled clinical terminologies must be combined under a common data model. We will finally provide research exemplars of EHR phenotypes being used for high-resolution clinical epidemiology studies. - 15h - 18h30m | Short course 2: Supervised/unsupervised learning methods in electronic health records research
- Venue: Instituto de Matemática e Estatística - Lab 140
- Leads: Maria Pikoula (University College London), Spiros Denaxas (University College London)
Abstract: This course will cover supervised and unsupervised statistical learning approaches applied to EHR. In the context of risk prediction and classification, we will discuss how supervised learning methods can be used to create and validate prognostic risk scores for predicting disease risk. Additionally, the course will cover methods commonly used in the discovery of clinically relevant disease subtypes, including the process of dimensionality reduction, clustering algorithms and clustering evaluation and validation. Finally, we will discuss the challenges, opportunities and best-practices of conducting these types of research studies in observational data from electronic health records. - 15h - 18h30m | Short course 3: Data linkage (vinculação de dados)
- Venue: Instituto de Matemática e Estatística - Lab 144
- Leads: Juracy Bertoldo (UFBA), Alberto Sironi (UFBA), Robespierre Pita (UFBA), Marcos Barreto (UFBA)
Abstract: This course will be organized in two parts. The first part concentrates on important concepts related to a data linkage pipeline, such as data quality (missing data), data preprocessing and linkage methods. We will discuss deterministic and probabilistic linkage methods, as well some uncertainty concepts related to probabilistic data linkage. Accuracy assessment will be discussed as an important step to certify linkage results. The second part will be practical, in which attendees will have access to a data linkage tool and will execute all the steps presented in a data linkage pipeline.